
Tento týždeň som začal pilotovať experiment s kojencami, takže dočasne fungujem v pohotovostnom režime. Tým pádom nemám moc času venovať sa Mozgostrojom. Dnes som doklepol aspoň jeden príspevok, ktorý by vám mal uľahčiť preklenúť toto ťažké obdobie.
V tomto príspevku nás zaujímajú neurónové siete z informatického hľadiska a preto sú na tomto mieste úvahy o ich biologickej alebo kognitívnej plauzibilite irelevantné. Ako píše Christopher Bishop (2006, s. 226) v úvode ku kapitole o neurónových sietiach:
The term ‘neural network’ has its origins in attempts to find mathematical representations of information processing in biological systems. Indeed, it has been used very broadly to cover a wide range of different models, many of which have been the subject of exaggerated claims regarding their biological plausibility. From the perspective of practical applications of pattern recognition, however, biological realism would impose entirely unnecessary constraints. Our focus in this chapter is therefore on neural networks as efficient models for statistical pattern recognition.
Striktne možno interpretovať neurónové siete ako viacúrovňové rozšírenie lineárnych modelov. Inováciou je, že výstup lineárneho modelu použijeme ako vstup do ďalšieho lineárneho modelu. Ak je teda v prípade lineárnej regresie model daný ako 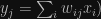


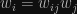

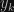

Tým sme hotový s formuláciou modelu a ideme optimalizovať parametre 
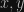


Nasleduje implementácia.
class NeuralNetwork():
"""
A simple two-layer neural network classifier
"""
def __init__(self,x,y,W):
""" N - nr of samples, M = nr of features+1
x - NxM numpy array, the first column is a vector of ones
y - NxL numpy array
W - (M+K+L)x(M+K+L) numpy array with weights, K nodes in the intermediate layer
"""
self.N=x.shape[0]
self.M=x.shape[1]
self.L = y.shape[1]
self.K = W[1].shape[0]
self.W1 = W[0]
self.W2= W[1]
self.x=x
self.y=y
def prediction(self,x=None,W=None):
if x is None: x=self.x
if W is None: W1=self.W1; W2=self.W2
else: W1,W2=W
self.a= -np.ones((x.shape[0],self.K))
#print self.a[:,1:].shape,x.shape,W1.shape
self.a[:,1:]=sigmoid(x.dot(W1))
return sigmoid(self.a.dot(W2))
def dE(self,W=None,x=None,y=None):
""" Error gradient of the data under
the current settings of parameters. """
if not x is None: self.x=x; self.y=y
if W is None: W1=self.W1; W2=self.W2
else: W1,W2=W
q=self.prediction()
d2=(1-q)*q*(q-self.y) # error at output
d1=(1-self.a)*self.a*d2.dot(W2.T)
dW1= np.zeros(W1.shape)
for i in range(dW1.shape[0]):
for j in range(dW1.shape[1]):
dW1[i,j]= d1[:,j].T.dot(self.x[:,i])
dW2= np.zeros(W2.shape)
for i in range(dW2.shape[0]):
for j in range(dW2.shape[1]):
dW2[i,j]= d2[:,j].dot(self.a[:,i])
return dW1,dW2
def checkCorrectness(self,xTest,yTest):
""" Gives performance in percent correct """
t = np.squeeze(yTest) > 0
y = np.squeeze(self.prediction(x=xTest) > 0.5)
return 100 * np.sum(t==y)/ np.size(yTest)
Neurónovú sieť môžeme rozbehnúť pomocou nasledujúceho algoritmu. Tento nepoužíva Newtonovu metódu. Parametre upravíme len na základe prvej derivácie vierohodnosti: 

K=2 # nr of hidden neurons
W1=np.random.randn(3,K)
W2=np.random.randn(K+1,1)
nn=NeuralNetwork(x,y,[W1,W2])
ynew=nn.prediction()
c0=0
eta= -0.0001
for i in range(20000):
dW1,dW2=nn.dE()
nn.W1+= eta*dW1
nn.W2+= eta*dW2
c1=(np.linalg.norm(dW1)**2+np.linalg.norm(dW2)**2)**0.5
if abs(c1-c0) if i%1000==0: print i,abs(c1-c0), nn.checkCorrectness(x,y)
c0=c1
Priestor parametrov je zaujímavý koncept. Pre každú konšteláciu hodnôt parametrov môžeme odmerať ich vierohodnosť. Vierohodnosť pridáme tiež ako dimenziu v priestore a ak tých dimenzii nie je moc veľa, môžeme priestor vizualizovať. Pre dva parametre môže vyzerať tento priestor nasledovne:

Optimalita modelu je väčšinou znázornená na vertikálnej osy. Oblasti vysokej vierohodnosti pritom tvoria kotliny (teda minimá). Koncept rozdelenia vierohodnosti v priestore parametrov sa netýka len neurónových sietí, ale optimalizácie parametrických modelov vo všeobecnosti. Napr. v kontexte genetických algoritmov sa tomuto priestoru hovorí aj “fitness landscape”, pričom vierohodnosť možno chápať ako fitness. Tak ako evolúcia optimalizuje fitness, takisto my hľadáme optimálne parametre pre náš model. Nezávisle od dimenzionality problému môžeme identifikovať určité kategórie rozdelení. Tieto kategórie nám umožnia lepšie pochopiť, prečo v niektorých prípadoch optimalizácia zlyhá.

A ukazuje najjednoduchší prípad monotónne konvexnej funkcie. Nech sa na začiatku nachádzame v hocakom bode stačí nám ísť stále dole kopcom a optimum (= minimálna hodnota funkcie) zaručene nájdeme. B a C ukazujú viaceré optimá. Pri B sú lokálne optimá plytké v porovnaní s globálnym optimom a so zopár trikmi môžeme vytvoriť algoritmus, ktorému sa z plytkých roklín podarí vybŕdnuť. Pri C a D je jedinou možnosťou skúsiť trénovať algoritmus s rôznymi počiatočnými hodnotami parametrov. Horšie je to v prípade E. Sútok lokálneho optima je široký oproti sútoku toho globálneho a tak väčšina inicializácii skončí uväznená v rokline lokálneho optima. Väčšina algoritmov vyžíva gradient vierohodnotsti (alebo inej objektívnej funkcie). Gradient nám povie, ktorým smerom sa bod (v priestore parametrov) zvažuje a teda ktorým smerom sa máme vybrať. Pri F, G a H stojíme na rovine a algoritmus nevie ktorým smerom sa vybrať. Môže sa napríklad stať, že bude chodiť v kruhu. G oproti F má izolované úzke optimum, ktoré by sa oplatilo nájsť. Algoritmus by však musel mať jasnovidecké schopnosti aby to dokázal. Pri H je situácia ešte horšia v tom, že úzkych optím je viacej. Takisto pri H povrch (bez tých úzkych dier) vykazuje určitý smer. Pri G teda aspoň môžeme zistiť, že náš algoritmus sa nepohol z miesta, lebo nenašiel žiadny svah. Pri F však môžeme nadobudnúť klamlivý dojem, že algoritmus konvergoval k optimu a pritom tento všetky zaujímavé optimá preskákal, lebo sú veľmi úzke.
Neurónovú sieť môžeme odskúšať na našom klasifikačnom probléme, ktorý som použil v prípade logistickej regresie. Náš algoritmus problém bez ďalších dodatočných trikov nevyrieši.

Problém je v tom, že parametre iniciujeme s hodnotami okolo nuly, pritom pozorované hodnoty ležia v oblasti s koordinátami (5,150). Aspoň niektoré parametre by mali byť inicializované s podobnými hodnotami. Neurónovej sieti môžeme pomôcť správnou inicializáciou (alebo alternatívne transformáciou dát).
nn.W1=np.array([[155,1,1],[155,0.01,1]]).T

Algoritmus nájde správne riešenie avšak ani v tomto prípade nie je perfektné (nelineárny model by teoreticky mohol vytvoriť ľubovoľnú deliacu krivku, nemusí isť o rovnú čiaru). Takisto algoritmus ho nenájde vždy – výsledok stále závisí od správnej inicializácie parametrov pre závažia smerujúce od skrytých uzlov k výstupnému uzlu.
Celý čas sme používali neurónovú sieť s dvoma dodatočnými skrytými uzlami, z ktorých každý je napojený na všetky vstupné a výstupné neuróny. Mohli by sme použiť viacej skrytých uzlov alebo pridať ďalšie vrstvy skrytých uzlov. Tým sa zlepší klasifikačný potenciáln neurónovej siete. Zároveň však stúpne dimenzionalita priestoru parametrov. Počet možných konštelácii hodnôt parametrov stúpa exponenciálne s dimenzionalitou, čím sa optimalizácia ďalej sťažuje.
Jednoduché neurónové siete sú dosť nešikovný model a málokedy sa dnes používajú na riešenie klasifikačných alebo regresných problémov. Historicky však neurónové siete inšpirovali viacero modelov kognitívnych procesov. K ich kognitívnej a biologickej plauzibilite a takisto k ich historickej roli v kognitívnych vedách sa vrátim v ďalších príspevkoch.
Bishop, C. (2006). Pattern Recognition and Machine Learning. Springer, New York.
